GPT 4.5 Released: Here Are the Benchmarks
With Grok 3 released last week and Claude 3.7 Sonnet just days ago, OpenAI up its games with a new model GPT-4.5 that prioritizes conversational abilities and emotional intelligence over pure reasoning power.

While it hasn't created the excitement of previous releases, GPT-4.5 offers some interesting capabilities that developers should understand before deciding whether to integrate it into their applications.
In this article, we will explore GPT-4.5's design, benchmarks, and real-world performance, and some tips on how to get the most out of it.
"Largest and Most Knowledgeable" Model
GPT-4.5 is OpenAI's latest model, described by the company as their "largest and most knowledgeable model yet." Unlike recent releases like o1 and o3-mini that focus on step-by-step reasoning, GPT-4.5 scales up unsupervised learning—which makes it better at conversation but weaker at complex problem-solving.
OpenAI has stated this will be their last model without built-in reasoning capabilities.
What's new with GPT-4.5?
- Improved Conversational Abilities: More natural dialogue with concise responses that feel less robotic
- Emotional Intelligence: Better at detecting user sentiment and responding appropriately to social cues
- Hallucinations Reduced: From GPT-4o's
61.8%on factual questions to37.1% - Better Knowledge: 62.5% accuracy on SimpleQA, significantly outperforming both GPT-4o and o1
Sam Altman's Take:
'It [GPT-4.5] is the first model that feels like talking to a thoughtful person to me' — Sam Altman, OpenAI's CEO
Developer's take
Developers find that GPT-4.5 excels at natural conversation and generating factual content, but struggles with systematic reasoning—at a premium price point. Specifically:
- Mixed Reasoning Performance: Outperforms GPT-4o but falls behind o3-mini on most reasoning tasks
- Surprising Coding Skills: Unexpectedly outperforms o3-mini on the SWE-Lancer benchmark for real-world coding tasks but underperforms on pure coding tasks
- Expensive API Pricing: $75 per million input tokens and $150 per million output tokens
GPT-4.5 Pricing vs. Leading Models
| Feature | GPT-4.5 | GPT-4o | o3-mini | Claude 3.7 Sonnet |
|---|---|---|---|---|
| Context Window | 128K tokens | 128K tokens | 128K tokens | 200K tokens |
| Max Output | 16,384 tokens | 4,096 tokens | 4,096 tokens | 4,096 tokens |
| Input Price | $75/M tokens | $5/M tokens | $5/M tokens | $3/M tokens |
| Output Price | $150/M tokens | $15/M tokens | $15/M tokens | $15/M tokens |
| Training Cutoff | April 2024 | October 2023 | October 2023 | April 2024 |
| Specialized For | Conversation & Knowledge | General Use | Reasoning | General Use |
| Vision Support | ✅ | ✅ | ✅ | ✅ |
| Function Calling | ✅ | ✅ | ✅ | ✅ |
| JSON Mode | ✅ | ✅ | ✅ | ✅ |
This makes GPT-4.5 significantly more expensive than alternatives like GPT-4o and even the pricy Claude 3.7 Sonnet, reflecting its computational demands.
Design and Architecture
OpenAI now builds better models by scaling two complementary paradigms:
- Reasoning (o-series models) - Teaches models to think step-by-step before responding
- Unsupervised learning (GPT series) - Increases world model accuracy and intuition
GPT-4.5 is an example of scaling the unsupervised learning approach. The model was trained on Microsoft Azure AI supercomputers, with architectural and optimization innovations allowing it to process and learn from massive amounts of data.
Benchmark Performance
Overall, GPT-4.5's excels in general knowledge and factual accuracy but shows more mixed results on reasoning-heavy tasks.
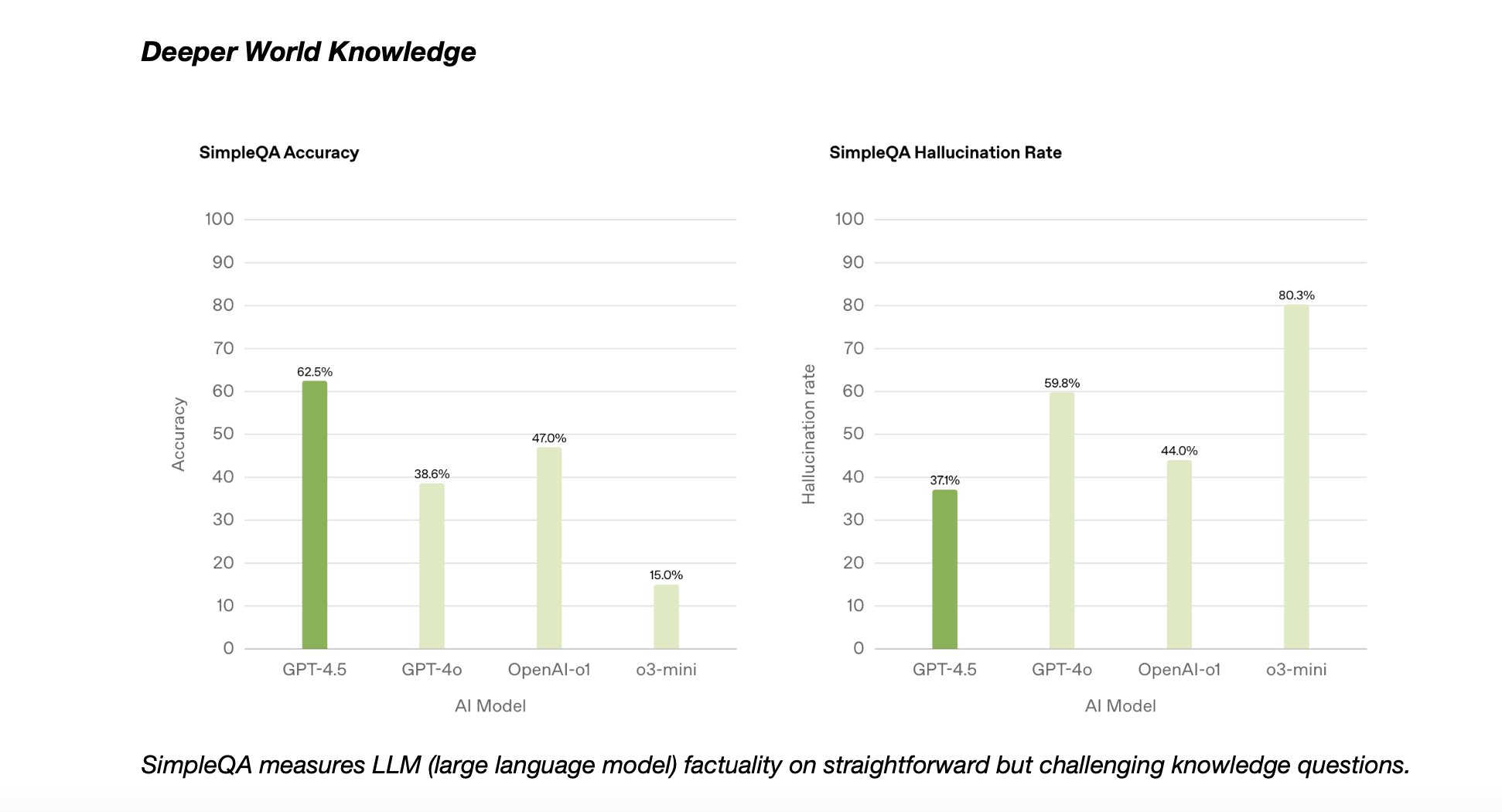
Knowledge and Factuality
On the SimpleQA benchmark, which measures factual accuracy on straightforward but challenging knowledge questions GPT-4.5 leads on accuracy and has the lowest Hallucination rates compared to other OpenAI models.
Reasoning Benchmarks
When it comes to tasks that typically benefit from reasoning, GPT-4.5 shows improvements over GPT-4o but falls behind reasoning-specialized models:
| Benchmark | GPT-4.5 | GPT-4o | OpenAI o3-mini |
|---|---|---|---|
| GPQA (science) | 71.4% | 53.6% | 79.7% |
| AIME '24 (math) | 36.7% | 9.3% | 87.3% |
| MMMLU (multilingual) | 85.1% | 81.5% | 81.1% |
| MMMU (multimodal) | 74.4% | 69.1% | - |
The results paint a clear picture: while GPT-4.5 significantly outperforms GPT-4o, it falls behind o3-mini on science and math tasks.
Our take 💡
GPT-4.5 is your best choice for factual knowledge and multilingual applications, but for complex math or science problems, o3-mini remains the superior option.
Coding Performance: The SWE-Lancer Surprise
The most intriguing benchmark results come from coding tests, where GPT-4.5 delivered some unexpected outcomes:
| Benchmark | GPT-4.5 | GPT-4o | OpenAI o3-mini |
|---|---|---|---|
| SWE-Lancer Diamond | 32.6% ($186,125) | 23.3% ($138,750) | 10.8% ($89,625) |
| SWE-Bench Verified | 38.0% | 30.7% | 61.0% |
The SWE-Lancer benchmark—which evaluates performance on real-world Upwork programming tasks—shows GPT-4.5 significantly outperforming not just GPT-4o but also o3-mini, which is surprising given o3-mini's reasoning advantages.
SWE-Lancer evaluates the ability to understand client requirements, interpret ambiguous instructions, and deliver solutions that satisfy human needs—areas where social awareness and emotional intelligence might provide an advantage.
This raises an interesting question: Could emotional intelligence be beneficial to AI when performing real-world coding tasks?
Quick note 💡
On SWE-Bench Verified, which focuses more on pure coding challenges rather than client-oriented tasks, o3-mini still dominates by quite a margin.
Emotional Intelligence & Human Evaluation
OpenAI conducted extensive human evaluations comparing GPT-4.5 to GPT-4o across different types of queries. The results show a strong preference for GPT-4.5:
- Professional queries: 70.8% preferred GPT-4.5
- Creative intelligence: 58.4% preferred GPT-4.5
- Everyday queries: 56.9% preferred GPT-4.5
These human evaluations align with what we've seen in practice: GPT-4.5's responses feel more natural, helpful, and attuned to user needs.
Real-World Performance
Beyond benchmarks, how does GPT-4.5 perform in actual use?
Early reception has been mixed, with some interesting strengths and weaknesses emerging.
The Strawberry Test
A simple but telling test done by Alex Northstar on X reveals GPT-4.5's struggle with basic reasoning.
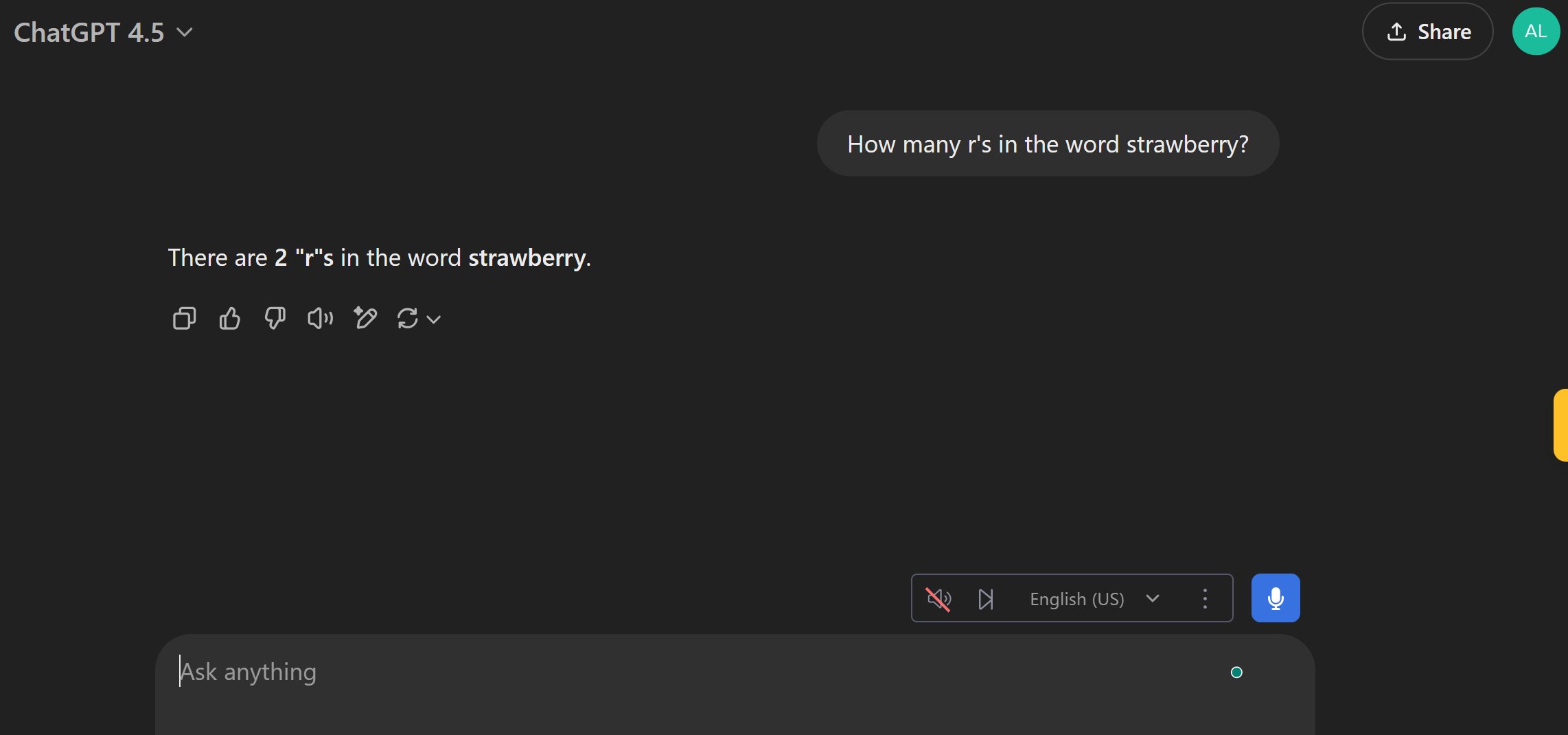
When asked "How many r's are in the word strawberry?", GPT-4.5 incorrectly answers "2", despite there being 3 r's in the word—as most reasoning models would tell you.
Mixed Reception
Let's pretend that we didn't see it and wait for GPT 5.
This comment (one of the most liked) on OpenAI's release video sums up many developers' reactions. This sentiment reflects the underwhelming nature of the release for those expecting groundbreaking new capabilities.
GPT-4.5's Unique Strengths
Despite these limitations, users report that GPT-4.5 excels in several areas:
- More concise responses: GPT-4.5 tends to be direct and to the point, avoiding the verbose explanations common in earlier models
- Better emotional intelligence: The model more accurately detects user emotions and responds appropriately
- Improved factual reliability: Fewer hallucinations when answering knowledge-based questions
- More natural conversation flow: Interactions feel less robotic and more human-like
- Writing: GPT-4.5 has been praised as one of the best available models for writing due to its more human-like style
How to Access GPT-4.5
GPT-4.5 is rolling out gradually due to GPU constraints, but here are all the ways you can access it through:
-
ChatGPT: Available now from the model picker for OpenAI ChatGPT Pro users ($200/month).
-
API: Chat Completions API, Assistants API, and Batch API. The API version supports all key features including function calling and JSON mode. GPT-4.5 currently does not support Voice Mode, video processing, or screensharing features in ChatGPT.
Monitor OpenAI Models with Helicone ⚡️
Track costs, usage patterns, and performance across all OpenAI models including GPT-4.5. Get started in minutes with just a single line of code.
from openai import OpenAI
client = OpenAI(
api_key="your-api-key",
base_url="https://oai.helicone.ai/v1"
)
response = client.chat.completions.create(
model="gpt-4.5-preview-2025-02-27",
messages=[
{"role": "user", "content": "What makes you different from GPT-4o?"}
]
)
print(response.choices[0].message.content)
Some guidelines on when to use GPT-4.5
Based on GPT-4.5's strengths and weaknesses, here are practical guidelines for when to use—and when to avoid—this model:
Best use cases
✅ Customer-facing chatbots and assistants: The improved conversational abilities and emotional intelligence make it excellent for direct user interaction
✅ Content generation: When tone, style, and emotional resonance matter
✅ Knowledge-based applications: For factual information retrieval with lower hallucination rates
✅ Multilingual applications: Given its strong MMMLU performance
✅ Client requirement interpretation: For understanding ambiguous or emotion-laden specifications
When to avoid GPT-4.5
🆇 Scientific or mathematical problem-solving: o3-mini significantly outperforms GPT-4.5 on GPQA and AIME benchmarks
🆇 Budget-conscious applications: The high token costs make GPT-4.5 prohibitively expensive for many use cases
🆇 Pure coding challenges: For systematic programming tasks, o3-mini's reasoning capabilities make it a better choice
🆇 Critical applications requiring perfect accuracy: The "strawberry test" failure demonstrates persistent reasoning limitations
Tips for optimization
- Use function calling for structured outputs to reduce token waste.
- Use a hybrid approach. For example, GPT-4.5 for user-facing components and o3-mini for back-end logic.
A tip for developers 💡
Consider using GPT-4.5 for front-end, user-facing components—like documentation or support assistance—while keeping reasoning models for back-end logic and complex problem-solving tasks.
Future Implications of GPT-4.5
GPT-4.5's release offers several insights into OpenAI's development strategy and the future of AI:
The last non-reasoning model
OpenAI has stated that GPT-4.5 will be their last non-reasoning model. This suggests that future releases will incorporate both strong reasoning capabilities and the improved conversational abilities demonstrated in GPT-4.5.
Is unsupervised learning reaching limits?
The modest improvements in GPT-4.5 despite enormous scaling raises questions about whether we're approaching diminishing returns from pure unsupervised learning. This could explain why OpenAI plans to incorporate reasoning in all future models.
Is Emotional Intelligence all you need?
The SWE-Lancer results suggest that emotional intelligence and reasoning abilities might be key to unlocking greater real-world performance from AI models.
You might also like:
- Technical Review: Claude 3.7 Sonnet & Claude Code
- OpenAI o3 Benchmarks and Comparison to o1
- OpenAI Deep Research & How it Compares to Perplexity
- Grok 3 Technical Review: Everything You Need to Know
Monitor the high costs of GPT-4.5 with Helicone
Helicone provides real-time cost tracking, token usage analytics, and caching to help optimize your implementation.
FAQs
What is the main difference between GPT-4.5 and o3-mini?
GPT-4.5 focuses on conversational abilities and emotional intelligence, while o3-mini excels at step-by-step reasoning for complex problems. GPT-4.5 has better knowledge retrieval and lower hallucination rates, but o3-mini performs better on math, science, and structured coding tasks.
What is the GPT-4.5's context window?
GPT-4.5 has a context window of 128k tokens with a max output token window of 16,384 tokens.
Is GPT-4.5 worth the higher cost compared to GPT-4o?
It depends on your use case. For user-facing applications where conversation quality matters, the improvement may justify the cost. For most technical applications, GPT-4o offers better value.
When will GPT-4.5 be available to all users?
OpenAI is rolling out GPT-4.5 gradually due to GPU constraints. It's currently available to Pro users, with Plus users gaining access next week, followed by Enterprise and Educational users.
Why does GPT-4.5 still make basic counting errors?
GPT-4.5's architecture focuses on pattern recognition and association rather than explicit reasoning. Without a step-by-step approach to solving problems, it can make errors in tasks that require precise counting or systematic analysis.
Why did OpenAI develop GPT-4.5 instead of focusing on reasoning capabilities?
OpenAI is pursuing two complementary approaches to AI advancement. While their o-series focuses on reasoning, GPT-4.5 represents their continued exploration of scaled unsupervised learning. This dual-track approach allows them to advance different aspects of AI capabilities simultaneously.
Questions or feedback?
Are the information out of date? Please raise an issue or contact us, we'd love to hear from you!